Transformer: Revolutionizing Machine Translation


Imagine a neural network that transforms how we process information, making tasks like language translation more accurate and training faster. That's the Transformer in a nutshell. Unlike its predecessors, the Transformer relies on attention mechanisms instead of traditional recurrent connections, allowing it to capture complex relationships within data.
In the rapidly evolving landscape of machine translation, the Transformer stands out as a groundbreaking neural network architecture. Developed with a sole reliance on attention mechanisms, this innovative approach has demonstrated superior effectiveness and efficiency compared to traditional architectures. In this blog post, we delve into the intricacies of the Transformer, comparing it to other neural network architectures and highlighting its advantages.
What is the Transformer?
The Transformer, introduced in the paper "Attention Is All You Need" by Vaswani et al. (2017), revolves around the concept of attention. This unique mechanism processes information by focusing on the most relevant parts, allowing the Transformer to excel in various tasks such as machine translation, text summarization, and question answering.
Understanding Attention Mechanisms
Imagine reading a sentence where certain words stand out more than others. These standout words are essential for grasping the meaning. Similarly, attention mechanisms in the Transformer act like a spotlight, emphasizing specific elements in a sequence.
Breaking Down the Jargon
1. Self-Attention:
- This mechanism allows each element in a sequence to focus on every other element.
- It's like each word in a sentence deciding which other words are most relevant.
2. Scaled Dot-Product Attention:
- The technical term for how the spotlight is applied.
- It involves calculating the relevance of each element by taking the dot product of its features.
Why Attention Matters
-
Context Understanding:
- Attention helps machines understand the relationships between different parts of data.
- It's like reading a paragraph and understanding how each sentence connects.
-
Enhanced Performance:
- The Transformer's attention mechanism outshines traditional methods, like recurrent connections.
- It's akin to upgrading from a standard flashlight to a spotlight—more focused and efficient.
Real-World Implications of Attention
Now, you might be wondering, "Why does this matter in the real world?" Understanding attention is crucial because it influences how machines process and comprehend information. From improving language translation accuracy to making sense of complex data, attention mechanisms lay the foundation for smarter and more efficient technology.
How does the Transformer compare?
The Transformer has proven to outperform conventional architectures, including the recurrent neural network (RNN), a widely used model for machine translation. Notably, the Transformer's training speed surpasses that of other architectures due to its independence from recurrent connections, which are often slower to train.
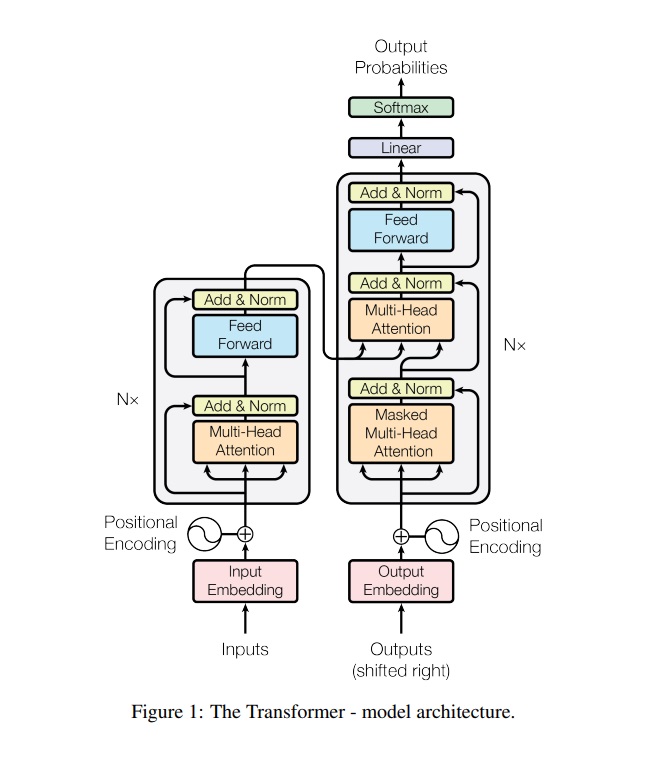
Advantages of the Transformer
The Transformer boasts several advantages over its counterparts in machine translation:
- Improved Accuracy: Demonstrates superior accuracy in machine translation tasks.
- Faster Training: Achieves quicker training times compared to other neural network architectures.
- Parallelization: Easily parallelizable, enabling simultaneous training on multiple GPUs or CPUs for accelerated performance.
Conclusion
The Transformer emerges as a promising neural network architecture, reshaping the landscape of machine translation. With its enhanced effectiveness and efficient training, the Transformer is poised to play a pivotal role in the future of language translation.
I trust this exploration of the Transformer has been insightful!
[Paper source] https://arxiv.org/abs/1706.03762
Connect with me on Twitter.
Please feel free to reach out if you have any questions or thoughts.